chrismorgan | 8 comments | 3 days ago
This is wrong, and harmfully wrong. OSI are not the arbiters of open source. Their Open Source Definition, though generally useful and accepted, is not without legitimate criticism and controversy. As for their approval, that’s a dreadful thing to rely on for any purpose; <https://writing.kemitchell.com/2019/05/05/Rely-on-OSI.html> is a good description of most of what’s wrong with it (it doesn’t really get into the broken politics enough; but some of his other articles contain more), and I like its summary: “The list of OSI-approved licenses reflects OSI’s practical and political history, not any useful, consistently functional category of license terms.”
As for whether SQLite is open source, well, the only reason a public domain dedication doesn’t meet the OSD is that it’s not a license. It’s more open. In a way that is legally mildly uncertain in some jurisdictions, sure, but to call it “not open source in the legal sense” is just wrong.
remram | 4 comments | 3 days ago
It's not "open source licensed" simply because it is not licensed. There is no license document for OSI to approve.
Relying on OSI approval does not necessarily make sense, they don't get to all licenses as your link points out. However arguing over their definition seems very foolish. People only do it when they want to pass their all-rights-reserved code as "open source" (e.g. "I can call it what I want"). Having adjectives that mean the same to everyone is very valuable, actually.
evanelias | 2 comments | 3 days ago
Yes, and that's precisely why OSI should have invented a brand new term which they could trademark. But instead they co-opted "open source" which already had a clear, generic meaning of "the source code is available", previously without any connotations around specific license terms. And then due to that prior usage of the term, OSI can't trademark it.
OSI created this terminology mess, and personally I don't think it is "foolish" to argue with their historical revisionism campaign around it.
Edit to add: for numerous proven examples of the term being used for many years prior to the OSI's existence, read the link ezekg already posted below, https://dieter.plaetinck.be/posts/open-source-undefined-part...
remram | 1 comment | 3 days ago
I also like the current terminology better tbh ("open", "available").
evanelias | 0 comments | 2 days ago
Instead we have a situation where they didn't invent the term but they lie about it and said they did. They don't have a trademark and obviously aren't a government agency, so enforcement is left to random people acting as self-appointed terminology police on their behalf. And then we get huge subthreads like this one, where a bunch of people have to argue about whether one of the most successful open source projects in history is really even "open source" :)
rat87 | 1 comment | 3 days ago
evanelias | 1 comment | 3 days ago
As for the pre-1998 meaning not being "clear", that's a matter of opinion. I would counter that OSI choosing to redefine an already existing term, and then falsely claim they invented that term, makes things far less clear.
Please read the link I included above. That post author's findings completely align with my own recollection from discussions on BBS's and newsgroups in the 90s.
remram | 1 comment | 2 days ago
I for one like where we are (which is not an endorsement of OSI as an organization, just of their definition). The terms are short and universally understood, there is a wide range of licenses to choose from, some of them even got a yay/nay from lawyers.
evanelias | 1 comment | 2 days ago
A fair number of vocal people in the industry express contempt for anything using a non-OSI license, even though many of these licenses are simply trying to empower a sustainable business model so the work can't be stolen and abused by cloud providers.
If you independently create a truly innovative new infrastructure software product today (or during any other non-ZIRP / non-boom-time period) with the intention of forming a company around it, you are faced with several bad options around licensing and source availability:
* If you adopt an OSI-approved license other than AGPL, and your product is successful, larger incumbents can and will steal your work and capture most of its value. You will either go out of business, or eventually need to re-license, causing mass outrage and accusations of rug-pulling.
* If you choose AGPL, most VC-funded companies won't touch your software and statistically it will almost certainly fail commercially as a result. Additionally there are several concerning theoretical loopholes in the AGPL, as well as conceptual problems with a non-EULA nonetheless trying to enforce restrictions affecting end users.
* If you choose an entirely close-sourced model, your chance of success is very very low, especially for B2B products. You're a small/new vendor, other companies won't trust you.
So the logical conclusion is you should choose a non-OSI license which prevents the cloud providers from stealing the profits from your hard work. But then random people will attack you everywhere for "open washing" and not being "open source", even if you don't use the word "open" anywhere. People have seemingly been trained to have a knee-jerk negative reaction to SSPL, BSL, etc and that's a really bad state of affairs.
It's especially problematic that the OSI is a closed-membership entity, and not an open-membership professional association. There is no democratic way for software engineers to influence its policies. As an industry we've effectively ceded control over what licenses are acceptable to a random small non-profit. And as a result of that, it's harder today to be a successful independent software vendor than it was in the 90s, which is an absurd state of affairs.
remram | 1 comment | 2 days ago
evanelias | 0 comments | 2 days ago
graemep | 0 comments | 3 days ago
That is true for most of us, but there are jurisdictions that do not recognise the public domain in the same way. SQLite's license page mentions this and offers licensing for people who need to deal with this. https://www.sqlite.org/copyright.html
avinassh | 2 comments | 3 days ago
OSI also says Public Domain is not open source: Public Domain Is Not Open Source https://opensource.org/blog/public-domain-is-not-open-source
wakawaka28 | 0 comments | 3 days ago
remram | 0 comments | 3 days ago
avinassh | 0 comments | 3 days ago
> As for whether SQLite is open source, well, the only reason a public domain dedication doesn’t meet the OSD is that it’s not a license. It’s more open.
That's true and I do acknowledge this in the post:
> Instead, SQLite is in the public domain, which means it has even fewer restrictions than any open source license.
[1] https://en.wikipedia.org/wiki/Open_source
[2] https://opensource.org/blog/public-domain-is-not-open-source
ezekg | 0 comments | 3 days ago
cryptonector | 2 comments | 3 days ago
saulpw | 2 comments | 3 days ago
Your idea is like saying "Google" can be a trademark owned by Alphabet but "google" is just a verb. It seems like a cute linguistic hack but won't be meaningful in the public discourse.
cryptonector | 1 comment | 3 days ago
In speech I clarify if and when needed, naturally.
> Your idea is like saying "Google" can be a trademark owned by Alphabet but "google" is just a verb. It seems like a cute linguistic hack but won't be meaningful in the public discourse.
You have it exactly backwards. Descriptively "to google" is a verb.
Descriptivism is much better than prescriptivism in natural language. Sure, we need to use prescriptivism when teaching the language, but we do get to evolve the language. That's just how it goes and has gone for the entire recorded history of mankind.
psychoslave | 1 comment | 3 days ago
cryptonector | 0 comments | 3 days ago
wat10000 | 1 comment | 3 days ago
chuckadams | 1 comment | 3 days ago
Clamchop | 1 comment | 2 days ago
Neither is pronouncing a capital letter, whatever that means. It's why people have to say things like "capital P Political".
wat10000 | 0 comments | 2 days ago
rad_gruchalski | 1 comment | 3 days ago
ska | 1 comment | 3 days ago
cryptonector | 1 comment | 3 days ago
mbreese | 1 comment | 3 days ago
cryptonector | 0 comments | 3 days ago
red_admiral | 2 comments | 3 days ago
The free as in freedom, but not as in free beer quadrant doesn't work too well, especially for individual developers.
dec0dedab0de | 0 comments | 3 days ago
Also, I believe that public domain as a concept does not exist in some countries. if i remember correctly the concern is that without a license the original author could change their mind and sue.
But any public domain software also matches the fsf and osi definition of free software and open source respectively. Atleast in jurisdictions where public domain exists.
You may be confusing things with copy-left, which is designed to protect users from developers. The gpl is a copy-left license.
sneak | 1 comment | 3 days ago
psychoslave | 0 comments | 3 days ago
Even the idea that whatever we dislike that gains more than zero popularity should be compared to a virus, this meme spreads like a virus.
gcau | 0 comments | 3 days ago
mschuster91 | 3 comments | 3 days ago
WaxProlix | 1 comment | 3 days ago
datavirtue | 1 comment | 3 days ago
sroussey | 1 comment | 3 days ago
datavirtue | 0 comments | 16 hours ago
red_admiral | 3 comments | 3 days ago
hermitdev | 3 comments | 3 days ago
I once had to go to lawyers to get a license approved on a lib that went something along the lines of "this work is in the public domain; do whatever the fuck you want with it, just don't come crawling to me for help". I'm paraphrasing from ~20-year-old memories here, but I do distinctly remember the profanity. It elicited a chuckle from the lawyer and something along the lines of "I wish all of these were this simple".
wat10000 | 0 comments | 3 days ago
IBM wanted to use it but their lawyers balked at the added restriction. They wrote to the author to see if it could be removed. The author wrote back with, “I give permission for IBM, its customers, partners, and minions, to use JSLint for evil.”
8organicbits | 0 comments | 3 days ago
emmelaich | 0 comments | 3 days ago
"DO WHAT THE FUCK YOU WANT TO PUBLIC LICENSE"
rcxdude | 0 comments | 3 days ago
monocasa | 1 comment | 3 days ago
jazzyjackson | 3 comments | 3 days ago
charrondev | 0 comments | 3 days ago
debugnik | 0 comments | 3 days ago
monocasa | 0 comments | 3 days ago
And legal departments don't really like the "but, like, what's the chance they actually use us?" argument.
belter | 2 comments | 3 days ago
Filligree | 2 comments | 3 days ago
somat | 3 comments | 3 days ago
Public domain is largely a US government concept, I think the was the main reason that sqlite was put "in the public domain" it started and was initially payed for as an internal database for some military contract. So when Dr. H wanted to release it to the public he did it in the normal US government method which was public domain.
Would you legally be able to use nasa papers or programs? these are also in the public domain.
A short essay on public domain, because I am feeling a bit philosophic this morning.
As far as I know public domain is a concept that originated in the US when it was a new country(probably wrong and US centric). The question was who owns works created by a government "of the people", the answer was "the people" so it was formalized that US government works were not protected by copyright[note 1] and were in the "public domain" at first this was just laws, and when government research organizations(nasa etc..) were founded their works, the research they did, was also "public domain"
It really is an open question whether private citizens can also declaim any copyright on a work, declare it "for the public good" and put it in the public domain. Are you allowed to give up your rights?
1. The US government is able to protect it's works through mechanisms other than copyright, think classification levels. top secret etc..
Filligree | 1 comment | 3 days ago
As for NASA papers and such... I have no idea. If I were running a company I'd be able to ask a lawyer; as it stands, I'm taking the risk that the SQLite authors don't sue.
bmacho | 0 comments | 3 days ago
Similar to physical property: being able to sell it or to give it to the public is an important right. (Okay, you probably can't give your American land to everyone in the world, but only for practical reasons, and not for some fundamental reason like that would be "giving away your rights". No, that would be the opposite: your land, you do whatever you want with it.)
shakna | 0 comments | 3 days ago
We're allowed to use public domain works, but we cannot declaim the work. Your copyright has a fixed term, which outlives you. Fin. You cannot surrender a right - as that has caused abuse issues in the past.
No right can be surrendered, but some may be suspended temporarily by a narrow set of laws I wish was even narrower.
Unfortunately... This does mean we can't work on Public Domain projects (legally), as we keep our copyright to our changes. Though practically, that has only been contested once in the history of the nation. The intent of the individual tends to be respected by our Common Law system.
i.e. PD is a signal the creator wants a free and boundless reuse of the product, even if it isn't strictly in the public domain.
wtallis | 0 comments | 3 days ago
rustc | 3 comments | 3 days ago
franga2000 | 0 comments | 3 days ago
The only part of the US public domain that won't fly in many countries is the waiver of moral rights (mainly the right to attribution). Since my country does not allow this waiver, the authors might be able to sue me in my jurisdiction if I started claiming to be the author of the code, which would have been ok in the US. But the voluntary non-exclusive transfer of usage, modification and distribution rights is surely allowed in every jurisdiction, so there is no reason that that part of the dedication would not be valid.
And if there exists a jurisdiction where the transfer of material rights isn't allowed at all, selling a license also wouldn't fix anything. Unless there's a jurisdiction out there somewhere that allows the transfer only in exchange for money or in a one-on-one contract, but then open source licenses also wouldn't apply there and I feel like I would've heard about it as a fun fact somewhere on the Internet by now...
Filligree | 0 comments | 3 days ago
However, on the face of it I have no right to use the software without buying a license.
nicbn | 0 comments | 3 days ago
causal | 0 comments | 3 days ago
hitekker | 4 comments | 3 days ago
As far as content goes, this listicle is probably great for view counts/engagement/flamewars. I'd personally prefer deeper thinking which this blog's previous posts-- high in hype and low in technical rigor-- have not yet provided.
avinassh | 7 comments | 3 days ago
Could you please state which are inaccurate? I am happy to correct them.
As for the rest of the comment, well, I don't know what to say. I am a beginner in databases and I am journaling the things I'm learning. Some of my posts might not have depth because I don't know much myself.
mtlynch | 2 comments | 3 days ago
>There are over one trillion (1000000000000 or a million million) SQLite databases in active use.
The original source[0] (which you don't link to):
>Since SQLite is used extensively in every smartphone, and there are more than 4.0 billion (4.0e9) smartphones in active use, each holding hundreds of SQLite database files, it is seems likely that there are over one trillion (1e12) SQLite databases in active use.
You're changing speculation to a fact.
Kwpolska | 1 comment | 3 days ago
avinassh | 1 comment | 3 days ago
In the initial draft, I kept links next to text and the images, but I didn't like it aesthetically. So I moved all them to the bottom.
Kwpolska | 0 comments | 3 days ago
There’s no good reason to use images in your post, other than the one graph. Images of text are a necessity on Twitter, but this is a real web page, where you can just have plaintext. Images of text are completely useless for readers with any accessibility needs.
avinassh | 1 comment | 3 days ago
this is simply untrue! This is the first link in the sources.
I do highlight this part specifically in the image as well.
mtlynch | 0 comments | 2 days ago
Also, you didn't address my main criticism, which is that you made a claim that's stronger than what your source says.
seritools | 1 comment | 3 days ago
SQLite _does_ support strict column types since 3.37: https://www.sqlite.org/stricttables.html
avinassh | 0 comments | 3 days ago
> Strong typed columns are opt-in.
I will rephrase this
chasil | 0 comments | 3 days ago
I believe that this was mentioned in the video below (I am not able to verify for now):
https://m.youtube.com/watch?v=Jib2AmRb_rk
It would be interesting to see what is required for an organization to negotiate non-trivial changes in SQLite.
kerblang | 2 comments | 3 days ago
https://en.wikipedia.org/wiki/Battleship https://en.wikipedia.org/wiki/Destroyer
themadturk | 0 comments | 3 days ago
avinassh | 0 comments | 3 days ago
I did not know about distinction, so TIL!
7thpower | 1 comment | 3 days ago
avinassh | 0 comments | 3 days ago
simplegeek | 0 comments | 3 days ago
xhkkffbf | 0 comments | 2 days ago
johnfn | 0 comments | 3 days ago
Really? Something like this[1] (literally the previous post made by the author!) is "high in hype and low in technical rigor"? Or do you just have an axe to grind?
radicalriddler | 0 comments | 3 days ago
bbkane | 0 comments | 3 days ago
As far as the content goes, this comment is probably great for view counts/engagement/flamewars. I'd personally prefer deeper thinking, which this author's previous comments-- usually fun and interesting-- have provided ;)
chrismorgan | 1 comment | 3 days ago
There was confusion over this, because of different usage of words. Simplifying well beyond the point of strict accuracy, a CoC is a weapon to bind and control external contributors’ behaviour, the CoE is SQLite developers declaring their intended conduct towards others.
> SQLite is pronounced as “Ess-Cue-El-Lite”.
This doesn’t match the quote that follows, which says “S-Q-L-ite, like a mineral”. And that’s just how one guy chooses to pronounce it… I wonder how many others do; certainly I’ve never heard it.
dkjaudyeqooe | 6 comments | 3 days ago
I believe the latter is the correct name for historical reasons. IBM originally named SQL 'SEQUEL' but were forced to rename it for trademark reasons.
So I pronounce SQLite sequelite.
chrismorgan | 1 comment | 3 days ago
This is by far the most popular pronunciation I’ve encountered, and I think by far the most practical one too.
tucnak | 1 comment | 3 days ago
lucasoshiro | 2 comments | 3 days ago
rphln | 0 comments | 3 days ago
Guilty as charged. Pronouncing letters and numbers in English requires an active mental effort for me, so that happens if I'm not paying attention. I guess it's because they don't really register as another language, even with context. My inner monologue also does letters and numbers in Portuguese, which doesn't help either.
Izkata | 1 comment | 3 days ago
quasarj | 0 comments | 3 days ago
conductr | 0 comments | 3 days ago
I feel like I made that shift due to how people around me, and how public speakers, were aligning on it too, it felt to me that the nomenclature was unifying a bit as linguistics evolve and change a bit over normal course of time. I remember the shift was not easy and I had to put intention into it and it took a bit of time to make it feel natural. Although, I’ve never thought about this too deeply and as I write it I’m Not sure how others would respond to my memory of it. I’m sure it’s very regional, and now age dependent as I’m sure if I was passed mid career at that time i wouldn’t have budged on my preferred terminology but also there’s many people who maybe are just too young to understand the time and trend that I remember. Or just my own experience and there was nothing really unifying at all.
somat | 1 comment | 3 days ago
(US/western, not coastal)
I pronounce it ess que lite.
and always letter out SQL.
postgresql is the tricky one, naively there is no good way to pronounce it. so when formal I say "postgres Q L" but mostly just call it postgres
and because of the previous cases I have started slurring mysql, easily the most pronounceable one into "mys Q L"
Microsofts SQL server (which I have never actually used, and almost never talk about) is simply "S Q L server"
breakingcups | 0 comments | 3 days ago
axus | 0 comments | 3 days ago
fatboy | 0 comments | 3 days ago
I'd always pronounced it in my head S-Q-L-Lite up until that point, but I much prefer this other way that I'd never considered. It rolls off the tongue easier and adds a bit of fancy.
bun_terminator | 1 comment | 3 days ago
I don't even know anymore, nor does anyone else I think
akavi | 0 comments | 3 days ago
jitl | 1 comment | 3 days ago
Like journal mode being ROLLBACK by default instead of WAL, foreign key constraints being off by default, tables being lax by default is part of SQLite’s dedication to backwards compatibility.
avinassh | 1 comment | 3 days ago
I did not, but probably I did not phrase correctly:
> Strong typed columns are opt-in.
jitl | 1 comment | 3 days ago
> 18. I hate that it doesn’t have types. It’s totally YOLO:
In the point where you say that you didn’t mention STRICT mode, which seems to directly address your complaint.
avinassh | 1 comment | 3 days ago
> It is “weakly typed”. SQLite calls it “type affinity”. Meaning you can insert whatever in a column even though you have defined a type. Strong typed columns are opt-in
and then I call it
> I hate that it doesn’t have types. It’s totally YOLO
ghusbands | 0 comments | 2 days ago
drzaiusx11 | 2 comments | 3 days ago
He was a pleasure to work with and it seemed he made a decent living just off of support contracts for projects like this. One of the few one-man-shops that really, really worked out.
Tempest1981 | 1 comment | 3 days ago
drzaiusx11 | 1 comment | 19 hours ago
The same project (nTAG Interactive LLC) also involved Brian Silverman who famously made a Babbage style mechanical computer capable of playing tick tac toe using only tinker toys for construction while he was still attending university. He also created the original Lego "computing brick" which ran Logo, a lisp-adjacent language, via interpreter/pcode vm he wrote using HC11 ASM (and later he ported to PIC for the "Cricket" robotics controller.) That brick project spun off into what is today Lego Mindstorms. So I've had the privilege of working with some very creative and intelligent folks over the years.
I had only stumbled into the opportunity by way of working as an assistant at my local university's robotics lab (to help pay for undergrad) when my professor thought I would be a good fit for the MIT Media Lab startup opening.
The job was a tremendously fun time and to this day I still think of it as my "favorite" work experience. Sadly, as with most startups, ours didn't make it when funding dried up, so the fun eventually ended. To be honest, I've been involved with a number of other early stage startups (and various larger size orgs) since and none have come close to the experience. There truly isn't anything better than being surrounded by folks who are masters at their craft and are willing to help you learn.
Tempest1981 | 0 comments | 7 hours ago
Imustaskforhelp | 2 comments | 3 days ago
I am interested in a thing where the whole programming language / program stack and everything is stored in the memory so you can have a language where it can run from where it was paused , inspired by some comment on some other hackernews thread . I had spent some of my weekends trying it but no use
drzaiusx11 | 0 comments | 19 hours ago
392 | 0 comments | 3 days ago
TekMol | 5 comments | 3 days ago
Since 2024, all my new database tables have only one column. Everything just goes into one single JSON column, which I always call "data".
SELECT
cities.data->>'name' city_name,
countries.data->>'name' country_name
FROM cities
JOIN countries
ON countries.data->'id' = cities.data->'country_id'
actuallyalys | 1 comment | 3 days ago
My understanding is that NoSQL databases still have indexes and it seems like using SQLite as you demonstrate could be worse in that regard.
TekMol | 1 comment | 3 days ago
reasoning behind having no id or key column
So far I have not used indexes because things are fast enough as they are. I would expect that when I need more speed, I can easily add indexes on expressions.
Why do you expect SQLite indexes on expressions to be worse than what NoSQL databases do for indexing?
actuallyalys | 1 comment | 2 days ago
> Why do you expect SQLite indexes on expressions to be worse than what NoSQL databases do for indexing?
I don’t have a concrete reason. It’s just that indexes on expressions are not intended as the main index for a SQLite database to my knowledge. Having thought about it more and read the page on expression indexes more thoroughly[0], I think it’s probably unlikely to be a noticeable downside.
The only remaining downside is that the item being indexed might be outright missing, but it sounds like that’s basically a feature in your case, as you’re opting for flexibility.
TekMol | 0 comments | 22 hours ago
RadiozRadioz | 1 comment | 3 days ago
So you have only just started doing this
breakingcups | 0 comments | 3 days ago
timewizard | 0 comments | 3 days ago
rafram | 2 comments | 3 days ago
advisedwang | 0 comments | 3 days ago
TekMol | 1 comment | 3 days ago
I can add a new attribute the very moment I create a new row.
When I want to add "not_available_before: 2026" to a car, I can do that right away. No need to alter the table and add a new column.
rafram | 2 comments | 3 days ago
TekMol | 1 comment | 3 days ago
I just named a downside of the columns approach: It slows things down.
Being able to add add fields faster leads to faster experimentation and development.
Althorion | 2 comments | 3 days ago
It will probably become a good idea then to have some clue as to what structure used to be at one point or the other, and for that you’d want to keep track as to what got added/removed and when.
If it’s a very early stage in the development, and you don’t expect any of the current data to survive to the final version, I guess that’s fine. But when you have an actual running product that has to keep running, dealing with the multiple versions of the data scheme is a pain, and dealing with the multiple untracked versions of the data scheme is a pain squared.
jitl | 0 comments | 2 days ago
Lots of use-cases for SQLite are not like Big Iron SQL Database Of Record where every change must be tracked because it's a shared stateful single point of failure and there's hell to pay for mistakes or confusion.
TekMol | 1 comment | 3 days ago
Althorion | 1 comment | 3 days ago
TekMol | 1 comment | 3 days ago
You seem to think that using columns somehow results in some type of automatic "tracking" (versioning?) of something.
Althorion | 1 comment | 3 days ago
It should be a multistep process. Yes, it will waste time now, but it will save it in a long run.
TekMol | 0 comments | 22 hours ago
MrLeap | 0 comments | 3 days ago
rob137 | 0 comments | 3 days ago
agilob | 1 comment | 3 days ago
tiffanyh | 1 comment | 3 days ago
https://www.sqlite.org/images/sschart20221116.jpg
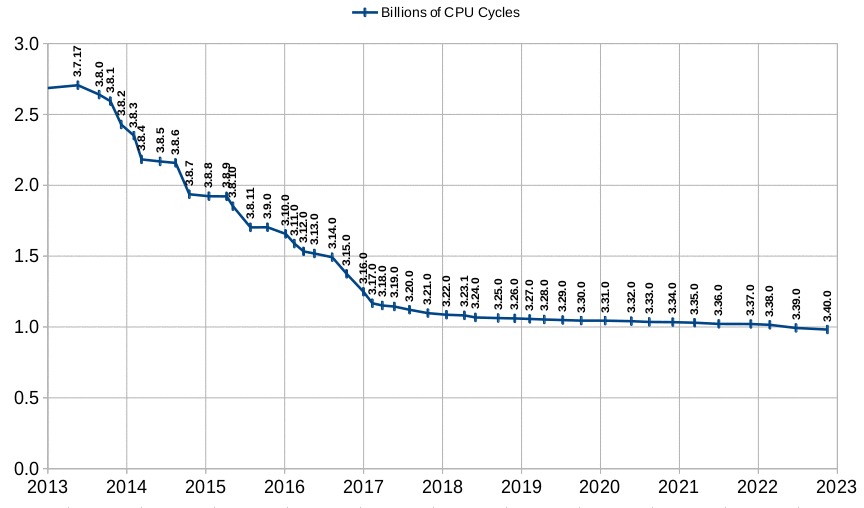{kind=link}
The bulk of the gains happened between 2013-2017.
didgetmaster | 2 comments | 3 days ago
x-complexity | 0 comments | 3 days ago
It's very much likely that the low hanging fruit's been picked clean, rather than the latter.
Take for example: You're given a bog standard codebase with no performance optimizations. It can be for whatever application, library, or service you could think of.
Running down the list of (increasingly not) obvious improvements:
- Removing duplicate work
- Multi-processing & multi-threading
- (if supported) Async I/O to remove I/O blocking
- Substituting data structures for more compact representations
- Understanding CPU caches & increasing cache hits
- (Very high effort - only as a last resort) Move to a compiled high perf language (C, Zig, Rust, etc.)
- (If applicable) Eliminating pointer use in code to prevent cache misses
- (If applicable) SIMD vectorization
- (If applicable) GPU processing
And each one of the above can only be done a certain amount of times: Once the improvement's been made, you can't gain the same boost by implementing it again exactly as before.
This isn't even mentioning that there's a base amount of work that needs to be done for a given task: Adding 2 numbers together requires at least 1 add instruction in x86 assembly, and you can't have 0 instructions.
What we're seeing here is that SQLite's hitting the floor: They likely can't go lower than this without a breakthrough in algorithms.
83457 | 1 comment | 3 days ago
agilob | 0 comments | 3 days ago
SigmundA | 2 comments | 3 days ago
Strange my recollection of the time was file based databases were much more popular. FoxPro, Access (jet) and Dbase where all in wide use in 90's and early 2000's and ran a lot of business software using network file shares instead of a database server.
vidarh | 7 comments | 3 days ago
That said, I'm not aware of anyone doing that with SQL before SQLite. Though I might well have missed some.
SigmundA | 0 comments | 3 days ago
It wasn't just used by MS Access, its was used from VB and other languages because it was just an ODBC/OLEDB driver.
https://en.wikipedia.org/wiki/Access_Database_Engine
FoxPro looks like it supported SQL in V2 in 1991
https://www.landley.net/history/mirror/collate/foxpro/foxpro...
Kwpolska | 1 comment | 3 days ago
colejohnson66 | 1 comment | 3 days ago
SigmundA | 0 comments | 2 days ago
> You can also create a Dynaset variable using an SQL string instead of the name of an existing table or query:
Dim db As Database, dsSomeData As Dynaset, SQL
Set db = OpenDatabase("NWIND.MDB")
SQL = "SELECT * FROM Employees WHERE Employees![City] = 'London';"
Set dsSomeData = db.CreateDynaset(SQL)
It had a nice visual builder for queries took me a while to appreciate writing them in SQL, many people never knew it was in there.
emmelaich | 0 comments | 3 days ago
There were also minimalist SQL interfaces to say BerkeleyDB and DBM around.
It was a rival of MySQL for a while. The article says "mSQL was the first low-cost SQL-based database management system" but notes citation needed. Certainly matches my memory though.
Home page: https://hughestech.com.au/products/msql/
[I thought it could run serverless but maybe that was very early versions if at all]
litoE | 0 comments | 3 days ago
beagle3 | 1 comment | 3 days ago
I also vaguely remember an optional SQL interface for Btrieve circa 1990, but I might be mistaken.
neverartful | 0 comments | 3 days ago
whartung | 0 comments | 3 days ago
We had it in an application written in C.
chasil | 0 comments | 3 days ago
danpalmer | 0 comments | 3 days ago
threatofrain | 0 comments | 3 days ago
pavel_lishin | 1 comment | 3 days ago
> This is one my favorite lore. SQLite had to default prefix from sqlite_ to etilqs_ when users started calling developers in the middle of the night
monktastic1 | 1 comment | 3 days ago
avinassh | 0 comments | 3 days ago
agilob | 1 comment | 3 days ago
As opposed to Redis (mentioned one line above the quote) which also is single-threaded?
zbentley | 0 comments | 2 days ago
andypants | 0 comments | 3 days ago
2010 is closer to sqlite's creation than today, not very recent
kerblang | 2 comments | 3 days ago
Maybe it's a nitpick, but a destroyer is not a battleship. The latter weren't even in service in the 2000's.
kstrauser | 1 comment | 3 days ago
kerblang | 0 comments | 3 days ago
avinassh | 0 comments | 3 days ago
I did not know about distinction, so TIL!
throw0101d | 0 comments | 3 days ago
I find the scientific notation of the counts amusing given the sometimes different meanings of "billion" and "trillion" (especially with English as a second language):
* https://en.wikipedia.org/wiki/Long_and_short_scales
* https://www.youtube.com/watch?v=C-52AI_ojyQ
* https://www.youtube.com/watch?v=WM1FFhaWj9w (bonus: on French numbers)
juneyi | 0 comments | 3 days ago
hakcermani | 0 comments | 3 days ago
panzi | 0 comments | 3 days ago
allo37 | 1 comment | 3 days ago
hellcow | 0 comments | 3 days ago
Tolexx | 1 comment | 3 days ago
swat535 | 0 comments | 2 days ago
red_admiral | 0 comments | 3 days ago
lambdaone | 1 comment | 3 days ago
Or some other calculation?
avinassh | 0 comments | 3 days ago
> Since SQLite is used extensively in every smartphone, and there are more than 4.0 billion (4.0e9) smartphones in active use, each holding hundreds of SQLite database files, it is seems likely that there are over one trillion (1e12) SQLite databases in active use.
nextworddev | 0 comments | 2 days ago
qwertox | 1 comment | 3 days ago
This is so remarkable and reminds me of my troubles with MongoDB and specially InfluxDB.
My MongoDBs are mostly still on 4.4 because of the complicated upgrade path (mostly related to the Python drivers), and InfluxDB is now officially split into 1.x and 2.x for me, where I have no plans for upgrading. And I specially will keep my hands off of 3.x because I've learned my lesson.
JonChesterfield | 1 comment | 3 days ago
ghusbands | 0 comments | 2 days ago
Svoka | 1 comment | 3 days ago
gs17 | 0 comments | 3 days ago
BobbyTables2 | 3 comments | 3 days ago
ElectricalUnion | 1 comment | 3 days ago
On more productive notes:
* Are you using WAL mode?
* Are you using Batch inserts/updates/upserts?
* Are you using `BEGIN IMMEDIATE` when you need DML? Suddenly upgrading from autocommit mode or `BEGIN DEFERRED` "DQL" transactions to `BEGIN IMMEDIATE` "DML" ones implicitly by suddenly starting DML on what used to be a sequence of DQL queries is bad on any database, but worse on SQLite;
wolfgang42 | 1 comment | 3 days ago
This is obviously incorrect, since Postgres can handle more than one simultaneous write transaction just fine. The rest of your post is accurate, but this is an intentional design decision to simplify SQLite’s implementation, not some fundamental limitation.